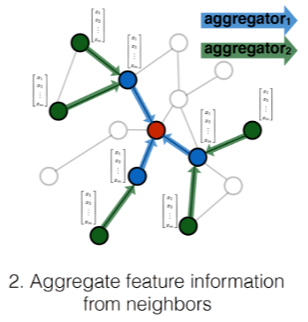
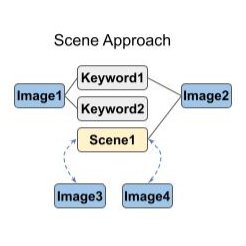
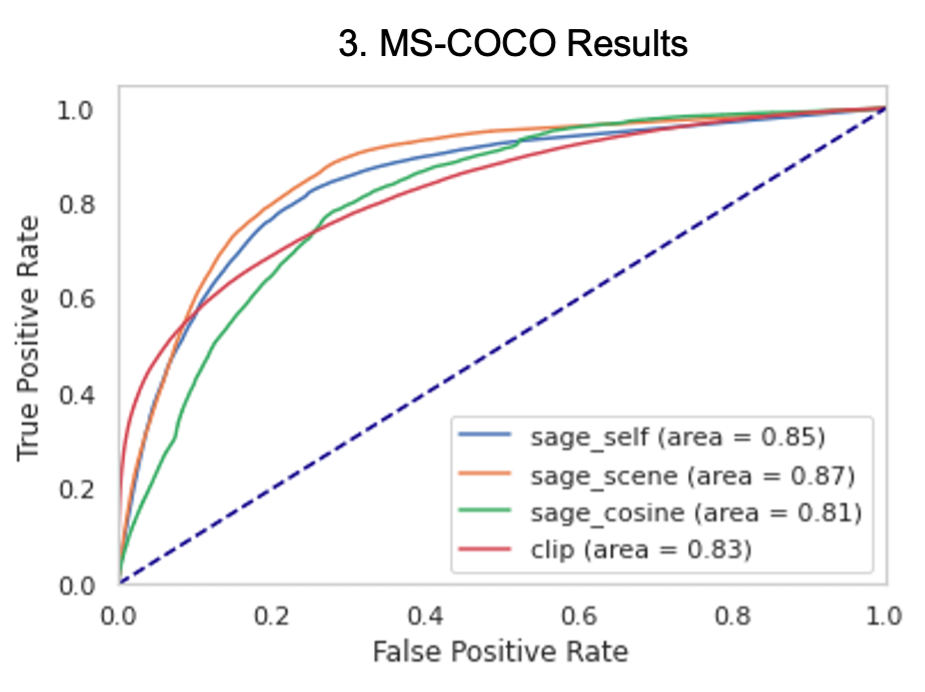
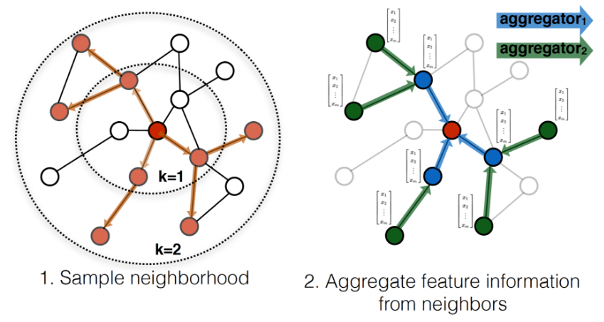
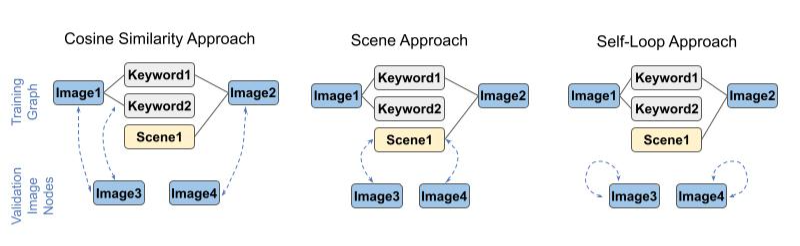
Research project developing inductive graph-based learning approaches to improve performance of multimodal (image + text) data representations for applications in Zillow Search. This was a joint effort by myself and fellow student researchers Adi Srikanth, David Roth, and Tanya Naheta under supervision of the Zillow Applied Science team and NYU.
Hi, I’m Andre.
Welcome to my portfolio! Below you can find personal projects I have worked on related to my academic and professional interests, which span from product data science to machine learning research in NLP and multimodal learning. You can visit my GitHub page to learn more.
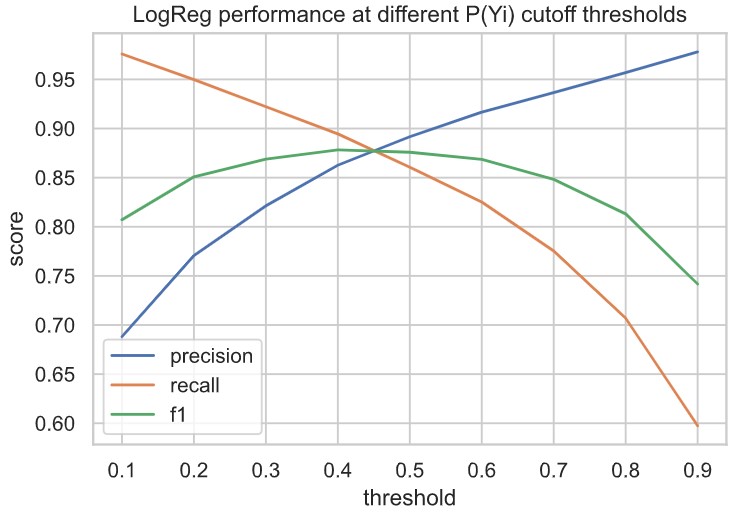
SimCSE Validation
Independent Validation and Extension of SimCSE Research Paper (Gao, Yao, and Chen 2021)
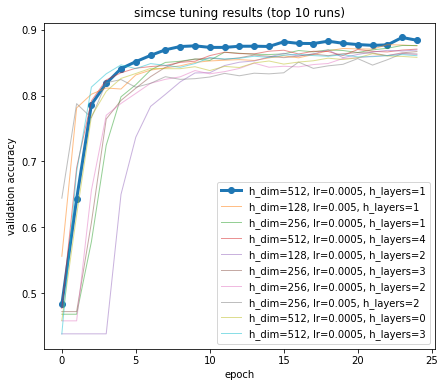
Contains work completed by myself, Adi Srikanth, and Jin Ishizuka validating and extending experimental results from SimCSE: Simple Contrastive
Learning of Sentence Embeddings by Gao, Yao, and Chen from Princeton University. Our work involved replicating experimental results from the paper,
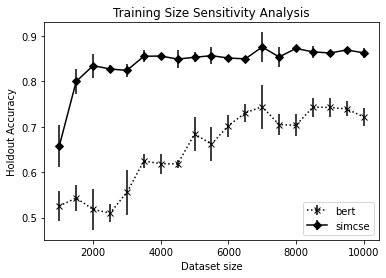
developing a neural sentiment classifier on scraped Twitter data to compare the performance of BERT and SimCSE-generated sentence embeddings as inputs,
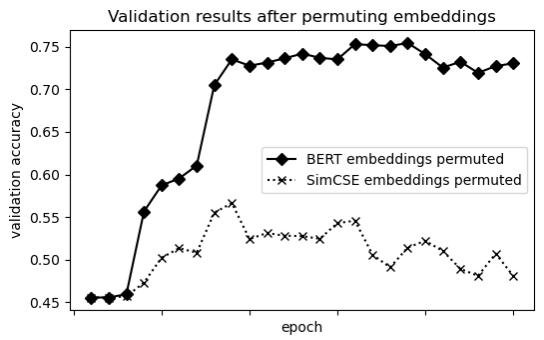
and evaluating BERT-based and SimCSE-based sentence encodings against each other using feature permutation analysis during sentiment classification.
Click [Read More] below to access source code and a full summary on data sources, methods, and results in the README of the project's GitHub repository.
Movie Recommender
Collaborative Filtering Movie Recommender System
Project exploring various ML-based approaches for building movie recommender system. Focus was on designing, building, and evaluating
latent factor models that could train in parallel on medium-large (+1 GB) distributed datasets on a high-performance computing cluster.
Models were trained on interactions data (ratings by 280,000 unique viewers on 58,000 unique movies) and evaluated based on how closely
their top 100 recommendations for each user matched their true top 100-ranked movies by rating.
Click [Read More] below to access source code and a full summary on data sources, methods, and results in the README of the project's GitHub repository.
contextify
ML-powered Playlist Generator
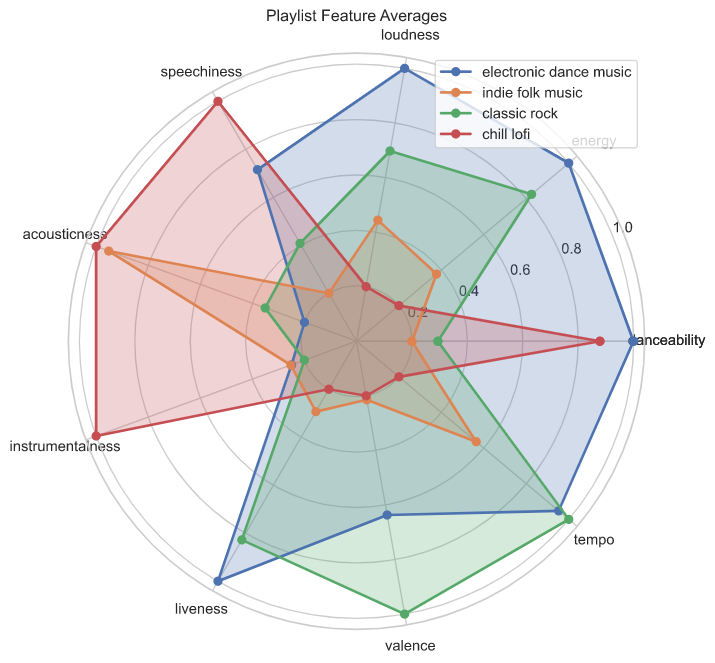
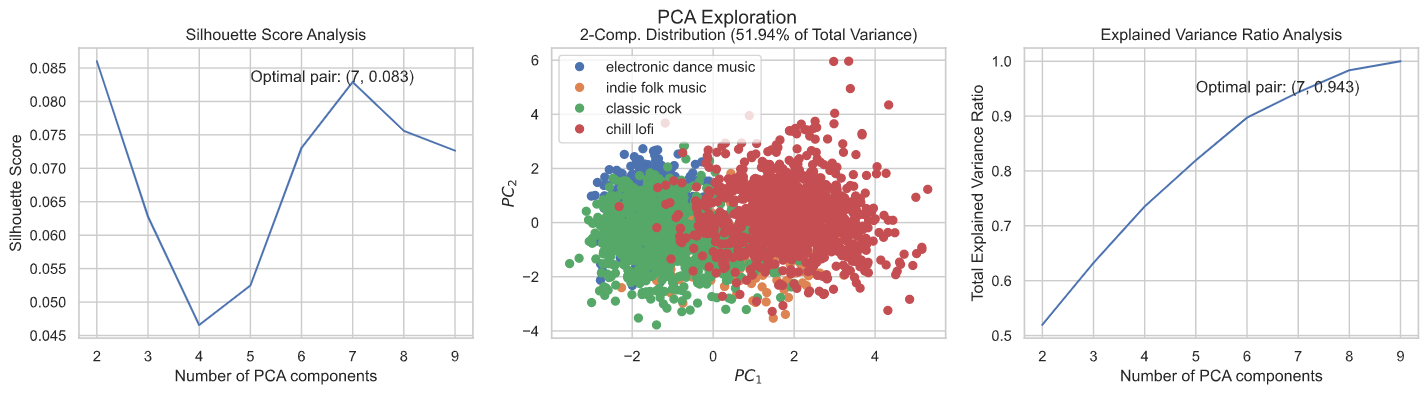
Interactive web application that uses logistic regression to sort any Spotify user’s Liked library
into playlists.
Flask / Plotly-Dash web application is live on AWS and available here:
http://contextify.us-east-1.elasticbeanstalk.com/
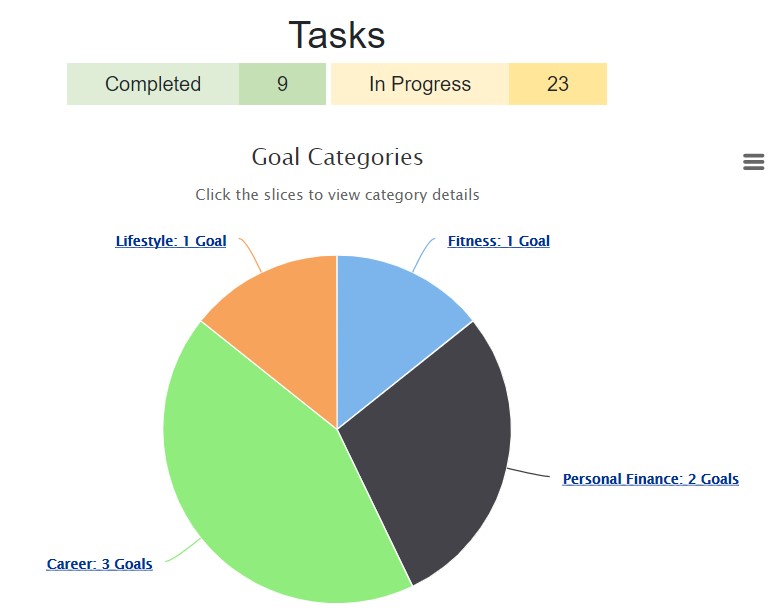
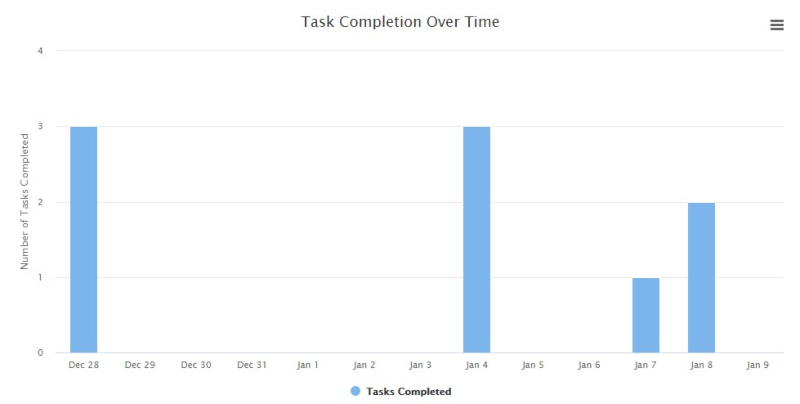
busybee
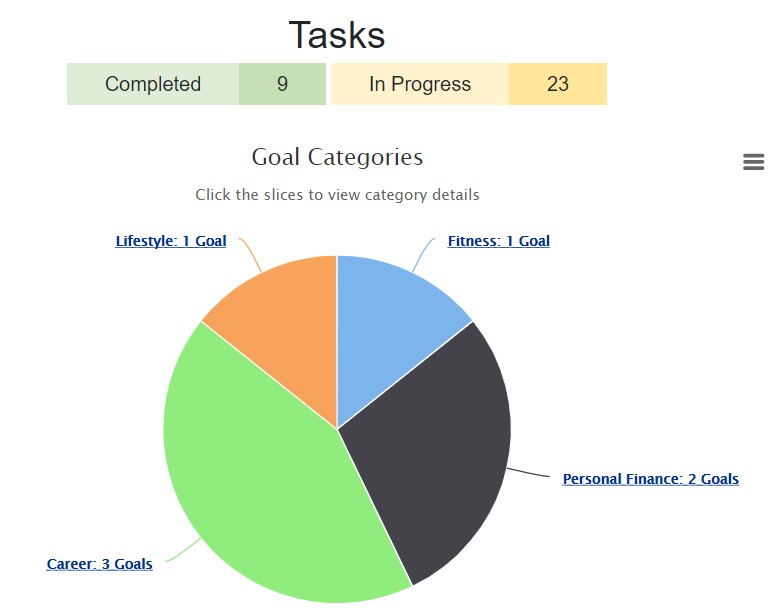
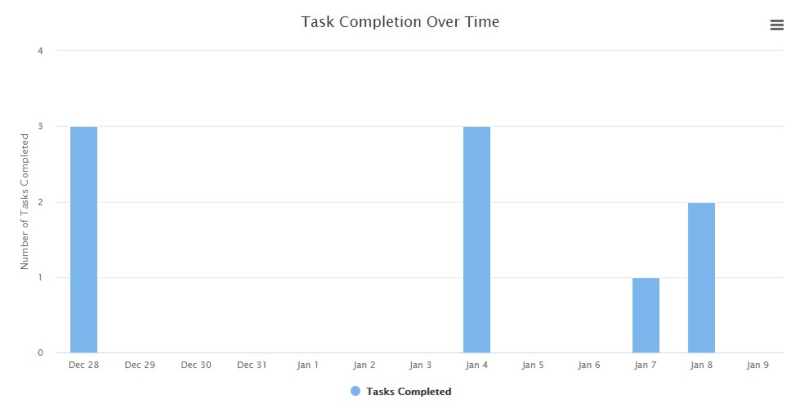
Data-Driven Productivity Tool
Full-stack, interactive web application to track your goals, subtasks, and completion rates in real
time.
Check it out on Google Cloud Platform:
(https://busybee-264219.appspot.com/)
For best results, login with these credentials:
username: test1 password: test
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
NFL Offensive Lineman Analysis
NFL Team Hackathon Submission
Use case development and prototyping of a solution using NFL’s NextGen player tracking data to generate valuable scouting and coaching insights for NFL teams.
[Read More]