Research project developing inductive graph-based learning approaches to improve performance of multimodal (image + text) data representations for applications in Zillow Search. This was a joint effort by myself and fellow student researchers Adi Srikanth, David Roth, and Tanya Naheta under supervision of the Zillow Applied Science team and NYU.
{kind=link}
{kind=link}
Executive Summary
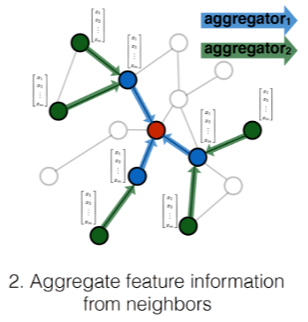
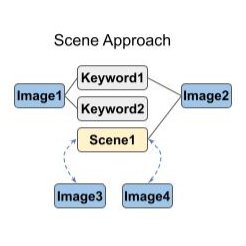
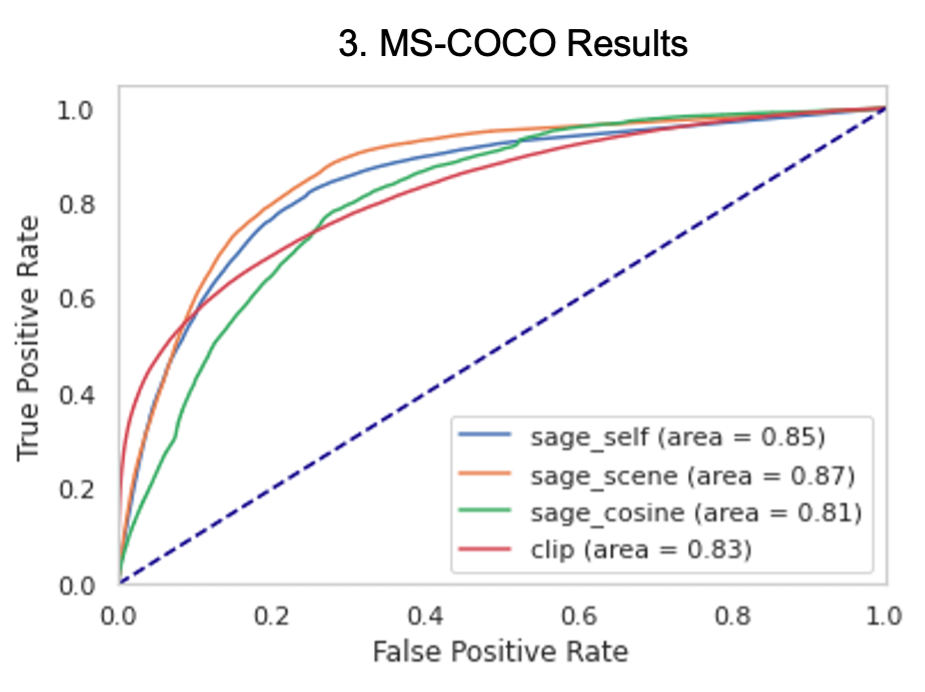
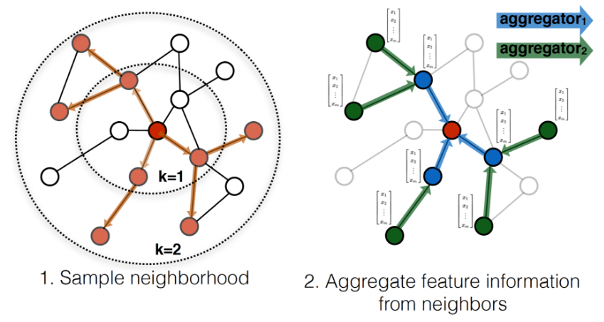
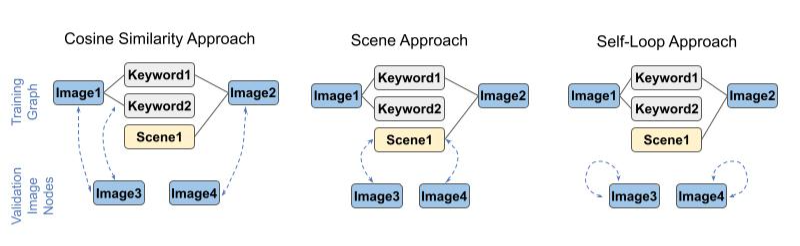
Multimodal graph-based learning approaches can facilitate a better search experience at Zillow, whose data is inherently multimodal (listing images, descriptions, and tags). As such, we used GraphSAGE, an inductive graph representation learning framework, to learn improved multimodal representations using CLIP-initialized node embeddings. Specifically, we trained a 2-layer GraphSAGE model using restricted fanout, mean aggregation, ReLU nonlinearity and batch normalization, then experimented with three approaches for connecting new, previously unseen nodes to the training graph during inference. Finally, we evaluated updated node embeddings on a cosine similarity-based image-keyword link prediction task and compared their performance to link prediction using embeddings initialized from a fine-tuned CLIP-ViT/32 as a baseline. We found that increasing connections to keyword labels during training improved GraphSAGE performance on out-of-vocabulary link prediction relative to baseline, and note that on MS-COCO, a well-known research dataset with human-generated keyword annotations, GraphSAGE generally outperformed our baseline.
You can read our final research paper here.
All code and documentation (scrubbed of proprietary Zillow information) is available on our Github repo.